Jun 7, 2023
Yes, PostgreSQL has problems, but we’re sticking with it!

Our previous blog article, “The Part of PostgreSQL We Hate the Most,” discussed the problems caused by everyone’s favorite street-strength DBMS multi-version concurrency control (MVCC) implementation. These include version copying, table bloat, index maintenance, and vacuum management. This article will explore ways to optimize PostgreSQL for each problem.
Although PostgreSQL’s MVCC implementation is the worst among other widely used databases like Oracle and MySQL, it remains our favorite DBMS, and we still love it! By sharing our insights, we hope to help users unlock the full potential of this powerful database system. The good news is that OtterTune automatically fixes a lot of these problems for you (but not all!).
Problem #1: Version copying
When a query modifies a tuple, regardless of whether it updates one or all of its columns, PostgreSQL creates a new version by copying all of its columns. This copying can result in significant data duplication and increased storage demands, particularly for tables with many columns and large row sizes.
Optimization: Unfortunately, there are no workarounds to address this issue without a significant rewrite of PostgreSQL’s internals that would be disruptive. It’s not like replacing a character on a sitcom that nobody notices. As mentioned in our previous article, EnterpriseDB started down this path with the zheap project in 2013, but the project’s last update was in 2021.
Others have made hard forks of the PostgreSQL code to replace its MVCC implementation. Notable examples include OrioleDB and YugabyteDB. But the changes to these systems will never get merged back into the main PostgreSQL codebase. So we’re stuck with PostgreSQL’s append-only MVCC for the time being.
Problem #2: Table bloat
PostgreSQL stores expired versions (dead tuples) and live tuples on the same pages. Although PostgreSQL’s autovacuum worker eventually removes these dead tuples, write-heavy workloads can cause them to accumulate faster than the vacuum can keep up. Additionally, the autovacuum only removes dead tuples for reuse (e.g., to store new versions) and does not reclaim unused storage space.
During query execution, PostgreSQL loads dead tuples into memory (since the DBMS intermixes them on pages with live tuples), increasing disk IO and hurting performance because the DBMS retrieves useless data. If you are running Amazon’s PostgreSQL Aurora, this will increase the DBMS’s IOPS and cause you to give more money to Jeff Bezos!
Optimization: We recommend monitoring PostgreSQL’s table bloat and then periodically reclaiming unused space. The pgstattuple built-in module accurately calculates the free space in a database but it requires full table scans, which is not practical for large tables in production environments.
Alternatively, one can estimate tables’ unused space using one-off queries or scripts; these are much faster and more lightweight than pgstattuple because they provide a rough estimation of table bloat. If the amount of unused space is substantial, the pg_repack extension removes and reclaims pages from bloated tables and indexes. It works online without requiring an exclusive lock on tables during processing (unlike VACUUM FULL).
The following commands will install the pg_repack extension into a self-managed DBMS (see Amazon’s instructions for PostgreSQL RDS) and then compact a single table.
To minimize the potential impact on database performance, OtterTune recommends that our customers initiate this process during off-peak hours when traffic is low.
Problem #3: Secondary index maintenance
When an application executes an UPDATE query on a table, PostgreSQL must also update all the indexes for that table to add entries to the new version. These index updates increase the DBMS’s memory pressure and disk I/O, especially for tables with numerous indexes (one OtterTune customer has 90 indexes on a single table!).
As the number of indexes in a table increases, the overhead incurred when updating a tuple increases. PostgreSQL avoids updating indexes for Heap-Only Tuples (HOT) updates, where the DBMS stores the new version on the same page as the previous version. But as we mentioned in our last article, OtterTune customers’ PostgreSQL databases only use the HOT optimization for 46% of update operations.
Optimization: The obvious fix to reduce PostgreSQL’s index write amplification is to reduce the number of indexes per table. But this is easier said than done. We recommend starting with duplicate and unused indexes in tables. One can identify duplicate indexes by examining a database’s schema to see if two indexes reference the same columns in the same order and use the same data structure (e.g., B+tree vs. hash table).
For unused indexes, PostgreSQL maintains index-level metrics (e.g., pg_stat_all_indexes.idx_scan) that track the number of index scans initiated on the index. If this value is zero for an index, then none of the applications’ queries use that index. Make sure that you ignore unused primary key or unique indexes, as the DBMS is using those to enforce integrity constraints on your tables.
The screenshot below shows OtterTune’s similar checks for automatically finding unnecessary indexes.
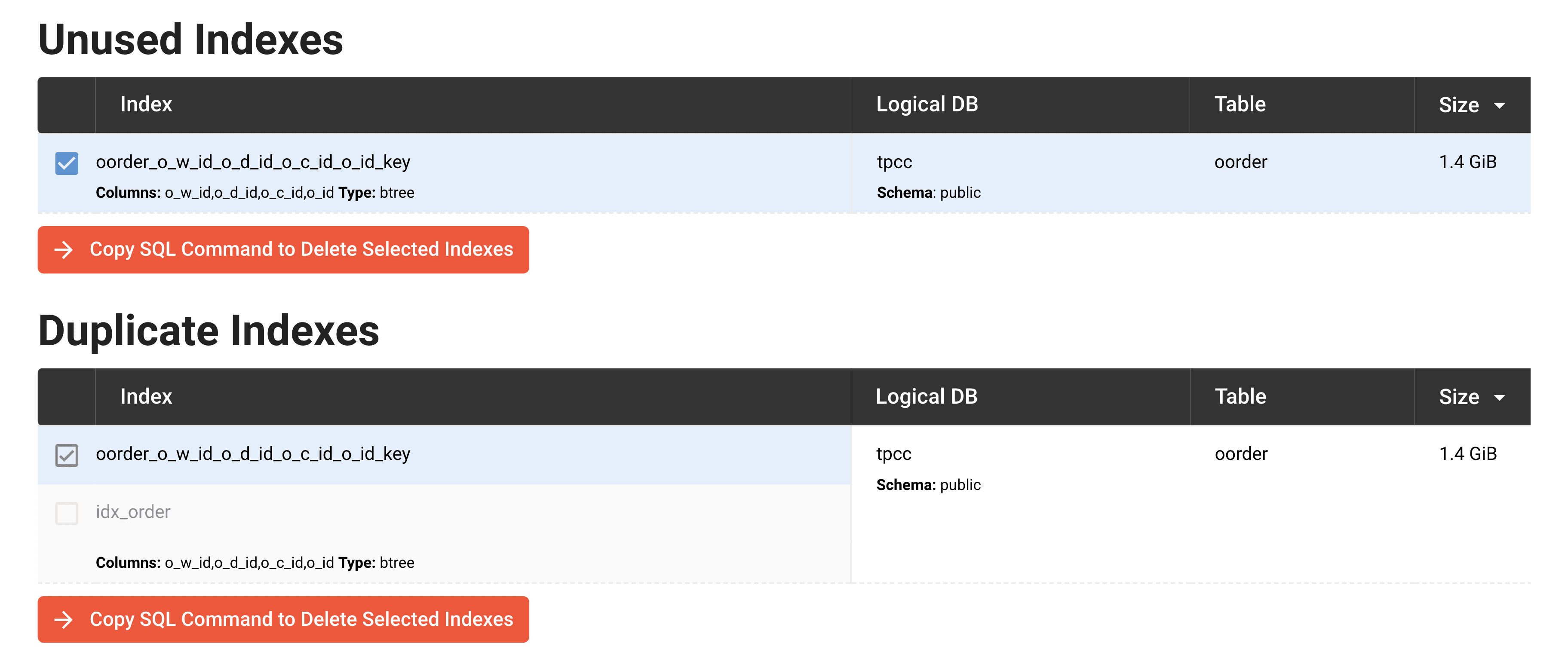
Once you identify indexes to drop, the next step is to remove them. However, if your application uses an Object-Relational Mapping (ORM) framework to manage its database schema, then you do not want to drop indexes manually because the ORM may recreate the indexes during future schema migrations. In such cases, it is necessary to update the schema in the application code. If the application is not using an ORM, then you can use the DROP INDEX command.
Problem #4: Vacuum Management
PostgreSQL’s performance heavily depends on the effectiveness of its autovacuum to clean up obsolete data and prune version chains in its MVCC scheme. However, configuring the autovacuum to operate correctly and remove this data in a timely manner is challenging due to its complexity. The default global autovacuum settings are inappropriate for large tables (millions to billions of tuples), as it may take too long before triggering vacuums.
Additionally, if each autovacuum invocation takes too long to complete or gets blocked by long-running transactions, the DBMS will accumulate dead tuples and suffer from stale statistics. Delaying the autovacuum for too long results in queries getting gradually slower over time, requiring manual intervention to address the problem.
Optimization: Although having to vacuum tables in PostgreSQL is a pain, the good news is that it is manageable. But as we now discuss, there are a lot of steps to this and a lot of information you need to track.
The first step towards taming the autovacuum is to monitor the number of dead tuples for each table. PostgreSQL’s pg_stat_all_tables view provides essential metrics for monitoring tables, including estimates for the number of dead tuples (n_dead_tup) and live tuples (n_live_tup). With such table-level metrics, you can determine the percentage of expired tuples per table and identify which tables need extra vacuum love.
For tables with a significant number of dead tuples, you can adjust their settings to enable PostgreSQL to trigger the autovacuum more frequently. PostgreSQL allows you to fine-tune the autovacuum parameters at the table level, and different tables may require different optimal settings.
The most important knob is autovacuum_vacuum_scale_factor: it specifies the minimal percentage of dead tuples in a table that must exist before PostgreSQL invokes the autovacuum on it. The default value for this knob is 20%. If one of your application’s tables has 1 billion tuples, PostgreSQL does not run the vacuum on that table until there are at least 200 million dead tuples. If the average tuple size in that table is 1KB, then 200 million dead tuples will consume 200GB of disk storage. And this does not even include additional storage overhead for index pointers to these tables!
To avoid this problem, you should set the scale factor knob for large tables to something smaller than 20% using the ALTER TABLE SQL command:
Next, you should check whether the autovacuum is getting blocked by long-running transactions. Once again, we can rely on PostgreSQL’s internal telemetry to get this information. The pg_stat_activity view provides real-time data on the current execution status of each PostgreSQL worker (i.e., process).
It shows how long each active transaction has been running. If a transaction has been running for several hours, you should consider killing it off so that the autovacuum can complete its operations. The example query below finds all the transactions that have been running for more than five minutes:
You can then kill the query using the pg_cancel_backend admin function:
Of course, there are possible unintended consequences from knocking out a query on the streets, so you must ensure that killing them will not cause problems in your application. To avoid the same problem in the future, make sure that the transaction’s queries are unnecessarily running longer because they are using inefficient query plans.
Refer to our previous articles on optimizing query performance, such as tricking out ORDER BY...LIMIT and running ANALYZE, to learn how to improve slow queries with OtterTune. You can also refactor your application to break up large transactions into smaller work units if you do not need them to be atomic (but admittedly, this is not always easy to do).
Lastly, you need to see whether there are long-running vacuum processes and then tune additional knobs. Similar to how pg_stat_activity shows you the status of PostgreSQL’s workers, the pg_stat_progress_vacuum view shows you the status of active autovacuum operations. With this view, you can determine whether a vacuum takes several hours or even days to finish. If your PostgreSQL DBMS does have long-running vacuums, then OtterTune recommends tuning three knobs:
The autovacuum_work_mem parameter specifies the maximum amount of memory the DBMS can use in each autovacuum invocation. Increasing this parameter can speed up the vacuum because it can prune more dead tuples per invocation.
The autovacuum_vacuum_cost_limit parameter controls how much I/O active autovacuum workers can incur before PostgreSQL forces them to back off for a while. A higher value for this knob means the autovacuum will be more aggressive.
Related to this cost-based control mechanism, the autovacuum_vacuum_cost_delay parameter determines how long an autovacuum worker must wait after the DBMS forces it to back off. A shorter delay means the autovacuum will return to action more quickly each time.