Apr 26, 2023
The part of PostgreSQL we hate the most

There are a lot of choices in databases (897 as of April 2023). With so many systems, it’s hard to know what to pick! But there is an interesting phenomenon where the Internet collectively decides on the default choice for new applications. In the 2000s, the conventional wisdom selected MySQL because rising tech stars like Google and Facebook were using it.
Then in the 2010s, it was MongoDB because non-durable writes made it “webscale“. In the last five years, PostgreSQL has become the Internet’s darling DBMS. And for good reasons! It’s dependable, feature-rich, extensible, and well-suited for most operational workloads.
But as much as we love PostgreSQL at OtterTune, certain aspects of it are not great. So instead of writing yet another blog article like everyone else touting the awesomeness of everyone’s favorite elephant-themed DBMS, we want to discuss the one major thing that sucks: how PostgreSQL implements multi-version concurrency control (MVCC).
Our research at Carnegie Mellon University and experience optimizing PostgreSQL database instances on Amazon RDS have shown that its MVCC implementation is the worst among the other widely used relational DBMSs, including MySQL, Oracle, and Microsoft SQL Server. And yes, Amazon’s PostgreSQL Aurora still has these problems.
In this article, we’ll dive into MVCC: what it is, how PostgreSQL does it, and why it is terrible. Our goal at OtterTune is to give you fewer things to worry about with your databases, so we’ve thought a lot about dealing with this problem. We’ll cover OtterTune’s solution for managing PostgreSQL’s MVCC issues automatically for RDS and Aurora databases in a follow-up article next week.
What is Multi-Version Concurrency Control?
The goal of MVCC in a DBMS is to allow multiple queries to read and write to the database simultaneously without interfering with each other when possible. The basic idea of MVCC is that the DBMS never overwrites existing rows. Instead, for each (logical) row, the DBMS maintains multiple (physical) versions.
When the application executes a query, the DBMS determines which version to retrieve to satisfy the request according to some version ordering (e.g., creation timestamp). The benefit of this approach is that multiple queries can read older versions of rows without getting blocked by another query updating it. Queries observe a snapshot of the database as it existed when the DBMS started that query’s transaction (snapshot isolation).
This approach eliminates the need for explicit record locks that block readers from accessing data while writers modify the same item.
David Reed’s 1978 MIT Ph.D. dissertation, “Concurrency Control in Distributed Database Systems,” was, we believe, the first publication to describe MVCC. The first commercial DBMS implementation of MVCC was InterBase in the 1980s. Since then, nearly every new DBMS created in the last two decades that supports transactions implements MVCC.
A systems engineer has to make several design decisions when building a DBMS that supports MVCC. At a high level, it comes down to the following:
How to store updates to existing rows.
How to find the correct version of a row for a query at runtime.
How to remove expired versions that are no longer visible.
These decisions are not mutually exclusive. In the case of PostgreSQL, it’s how they decided to handle the first question in the 1980s that caused problems with the other two that we still have to deal with today.
For our discussion, we will use the following example of a table containing movie information. Each row in the table includes the movie name, release year, director, and a unique ID serving as the primary key, with secondary indexes on the movie name and director. Here is the DDL command to create this table:
The table contains a primary index (movies_pkey) and two secondary B+Tree indexes (idx_name, idx_director).
PostgreSQL’s Multi-Version Concurrency Control
As discussed in Stonebraker’s system design document from 1987, PostgreSQL was designed from the beginning to support multi-versioning. The core idea of PostgreSQL’s MVCC scheme is seemingly straightforward: when a query updates an existing row in a table, the DBMS makes a copy of that row and applies the changes to this new version instead of overwriting the original row.
We refer to this approach as the append-only version storage scheme. But as we now describe, this approach has several non-trivial implications in the rest of the system.
Multi-Versioned Storage
PostgreSQL stores all row versions in a table in the same storage space. To update an existing tuple, the DBMS first acquires an empty slot from the table for the new row version. It then copies the row content of the current version to the new version, and applies the modifications to the row in the newly allocated version slot. You can see this process in the example below when an application executes an update query on the movies database to change the release year of “Shaolin and Wu Tang” from 1985 to 1983:
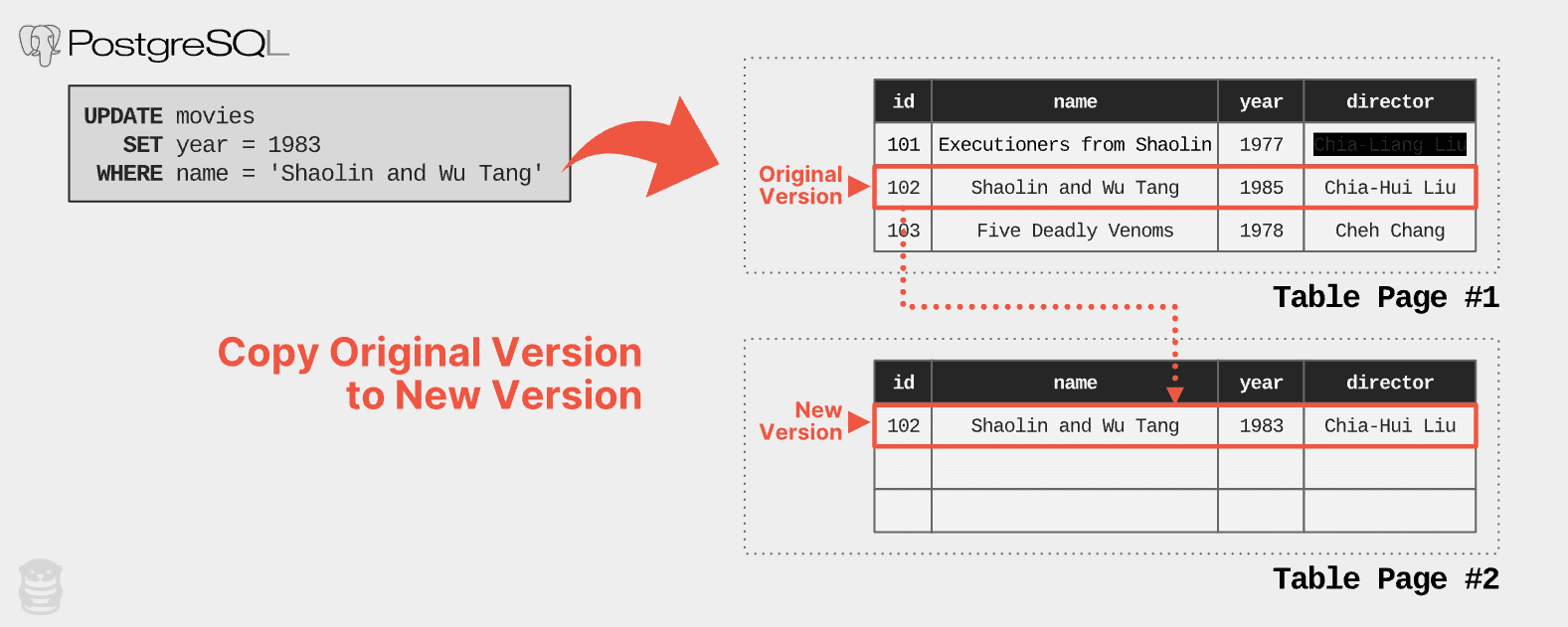
When an UPDATE query changes a tuple in the table, PostgreSQL copies the original version of the tuple and then applies the change to the new version. In this example, there is no more space in Table Page #1, so PostgreSQL creates the new version in Table Page #2.
Now with two physical versions representing the same logical row, the DBMS needs to record the lineage of these versions so that it knows how to find them in the future. MVCC DBMSs achieve this by creating a version chain via a singly linked-list. The version chain only goes in one direction to reduce storage and maintenance overhead. This means that the DBMS has to decide what order to use: newest-to-oldest (N2O) order or oldest-to-newest (O2N).
For the N2O order, each tuple version points to its previous version and the version chain’s head is always the latest version. For the O2N order, each tuple version points to its new version, and the head is the oldest tuple version. The O2N approach avoids the need for the DBMS to update indexes to point to a newer version of the tuple each time it’s modified.
However, it may take longer for the DBMS to find the latest version during query processing, potentially traversing a long version chain. Most DBMSs, including Oracle and MySQL, implement N2O. But PostgreSQL stands alone in using O2N (except for Microsoft’s In-Memory OLTP engine for SQL Server).
The next issue is how PostgreSQL determines what to record for these version pointers. The header for each row in PostgreSQL contains a tuple id field (t_tcid) of the next version (or its own tuple id if it is the latest version). Thus, as shown in this next example, when a query requests the latest version of a row, the DBMS traverses the index, lands on the oldest version, and then follows the pointer until it finds a version that it needs.
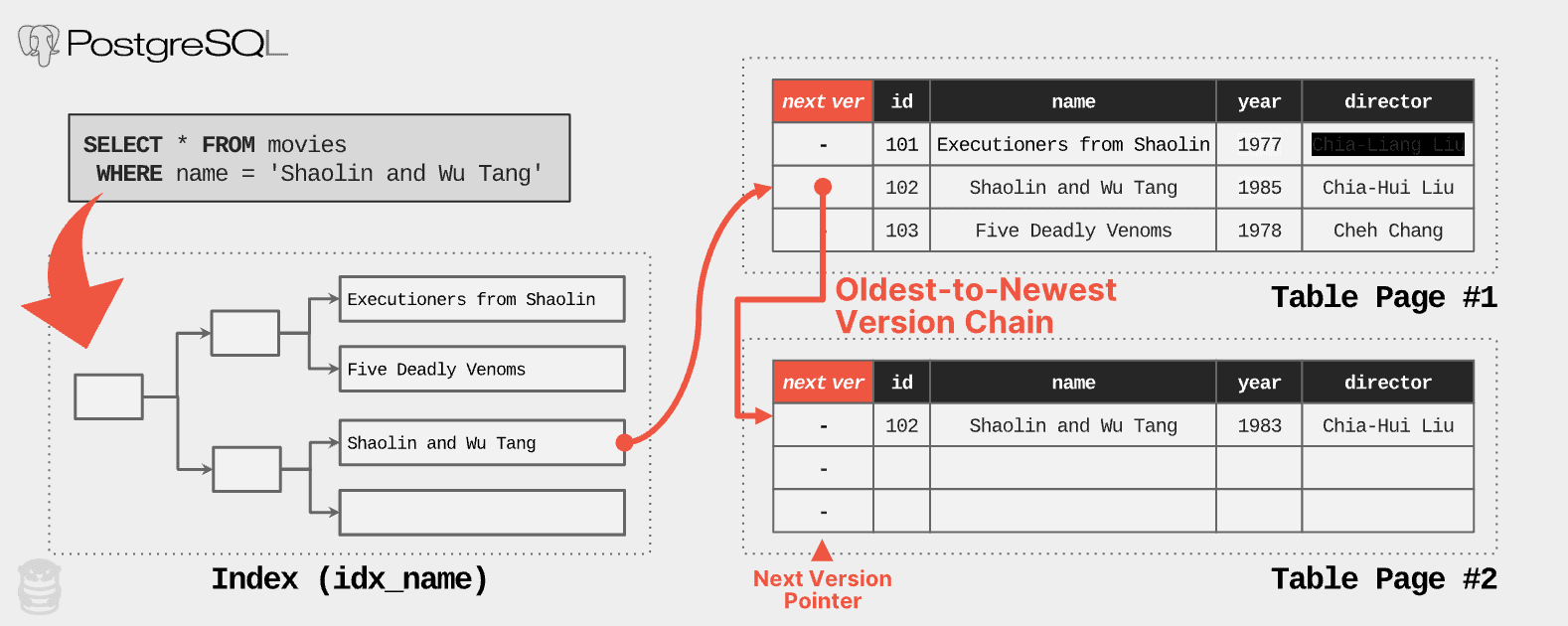
The SELECT query traverses the index to find tuple with requested movie name. The index entry points to the oldest version of the tuple, which means PostgreSQL follows the version chain embedded in the original version to find the new version.
PostgreSQL developers realized early on that there are two problems with its MVCC scheme. First, making a new copy of an entire tuple every time it is updated is expensive. And second, traversing the entire version chain just to find the latest version (which is what most queries want) is wasteful. Of course there is also the problem of cleaning up old versions, but we’ll cover that below.
To avoid traversing the entire version chain, PostgreSQL adds an entry to a table’s indexes for each physical version of a row. That means if there are five physical versions of a logical row, there will be (at most) five entries for that tuple in the index! In the example below, we see that the idx_name index contains entries for each of the “Shaolin and Wu Tang” rows that are on separate pages. This enables direct access to the latest version of the tuple, without the need to traverse the long version chain.
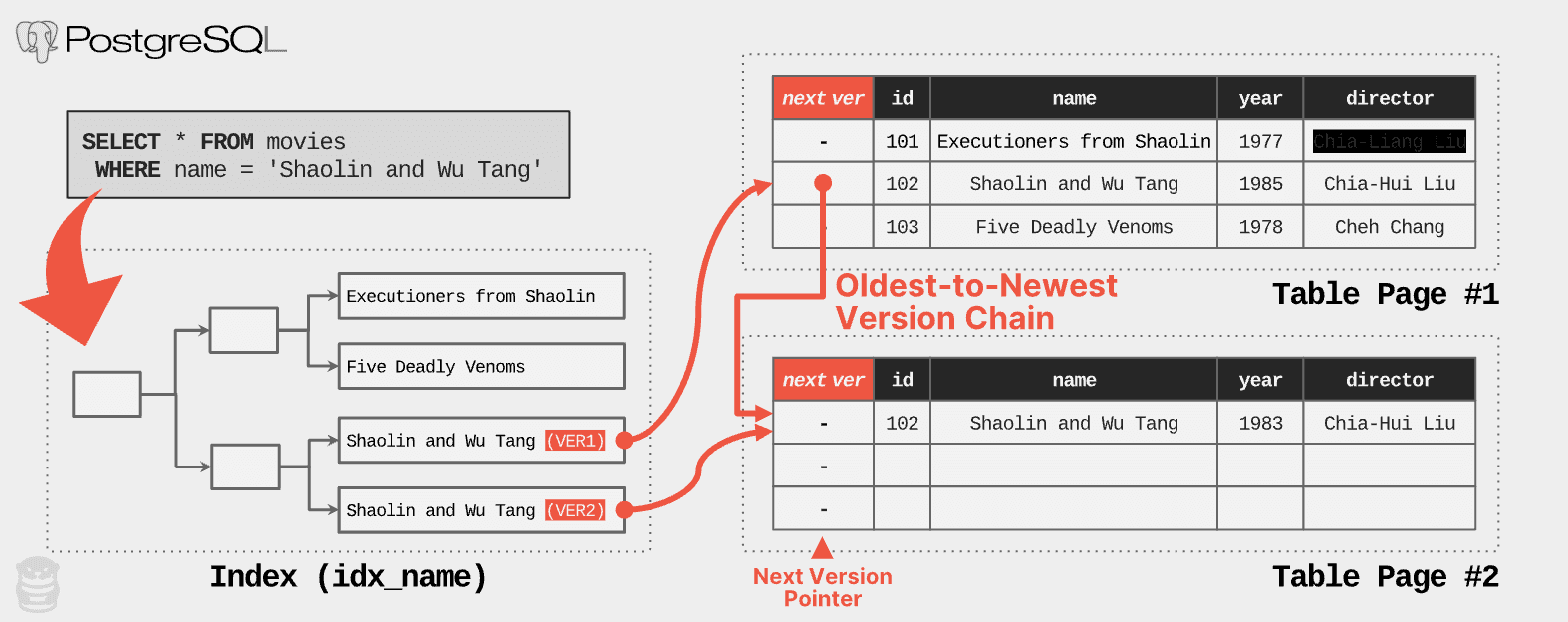
In this example, the index contains multiple entries for the “Shaolin and Wu Tang” tuple (one for each version). Now PostgreSQL uses the index to find the latest version and then immediately retrieves it from Table Page #2 without having to traverse the version chain starting at Table Page #1.
PostgreSQL tries to avoid having to install multiple index entries and storing related versions over multiple pages by creating a new copy in the same disk page (block) as the old version to reduce disk I/O. This optimization is known as heap-only tuple (HOT) updates. The DBMS uses the HOT approach if an update does not modify any columns referenced by a table’s indexes and the new version is stored on the same data page as the old version (if there is space in that page).
Now in our example, after the update the index still points to the old version and queries retrieve the latest version by traversing the version chain. During normal operation, PostgreSQL further optimizes this process by removing old versions to prune the version chain.
Version vacuum
We’ve established that PostgreSQL makes a copy of rows whenever an application updates them. The next question is how the system removes older versions (called “dead tuples”). The original version of PostgreSQL from the 1980s did not remove dead tuples. The idea was that keeping all the older versions allowed applications to execute “time-travel” queries to examine the database at a particular point in time (e.g., run a SELECT query on the state of the database as it existed at the end of last week).
But never removing dead tuples means tables never shrink in size if the application deletes tuples. It also means long version chains for frequently updated tuples, which would slow down queries, except that PostgreSQL adds index entries that allow queries to quickly jump to the correct version instead of traversing the chain. But now, this means the indexes are larger, making them slower and adding additional memory pressure. Hopefully, you can understand now why all these issues are interconnected.
To overcome these problems, PostgreSQL uses a vacuum procedure to clean up dead tuples from tables. The vacuum performs a sequential scan on table pages modified since its last run and find expired versions. The DBMS considers a version “expired” if it is not visible to any active transaction. This means no current transaction is accessing that version, and future transactions will use the latest “live” version instead. Thus, removing the expired version and reclaiming the space for reuse is safe.
PostgreSQL automatically executes this vacuum procedure (autovacuum) at regular intervals based on its configuration settings. In addition to the global settings that affect the vacuum frequency for all tables, PostgreSQL provides the flexibility to configure autovacuum at the table level to fine-tune the process for specific tables. Users can also trigger the vacuum manually to optimize database performance via the VACUUM SQL command.
Why PostgreSQL’s MVCC is the worst
We will be blunt: if someone is going to build a new MVCC DBMS today, they should not do it the way PostgreSQL does (e.g., append-only storage with autovacuum). In our 2018 VLDB paper (aka “the best paper ever on MVCC“), we did not find another DBMS doing MVCC the way PostgreSQL does it. Its design is a relic of the 1980s and before the proliferation of log-structured system patterns from the 1990s.
Let’s talk about four problems that arise with PostgreSQL’s MVCC. We will also talk about why other MVCC DBMSs like Oracle and MySQL avoid these problems.
Problem #1: Version copying
With the append-only storage scheme in MVCC, if a query updates a tuple, the DBMS copies all its columns into the new version. This copying occurs no matter if the query updates a single or all of its columns. As you can imagine, append-only MVCC results in massive data duplication and increased storage requirements. This approach means that PostgreSQL requires more memory and disk storage to store a database than other DBMS, which means slower queries and higher cloud costs.
Instead of copying an entire tuple for a new version, MySQL and Oracle store a compact delta between the new and current versions (think of it like a git diff). Using deltas means that if a query only updates a single column in a tuple for a table with 1000 columns, then the DBMS only stores a delta record with the change to that one column. On the other hand, PostgreSQL creates a new version with the one column that the query changed and the 999 other untouched columns. We will ignore TOAST attributes because PostgreSQL handles them differently.
There was an attempt to modernize PostgreSQL’s version storage implementation. EnterpriseDB started the zheap project in 2013 to replace the append-only storage engine to use delta versions. Unfortunately the last official update was in 2021, and to the best of our knowledge the effort has fizzled out.
Problem #2: Table bloat
Expired versions in PostgreSQL (i.e., dead tuples) also occupy more space than delta versions. Although PostgreSQL’s autovacuum will eventually remove these dead tuples, write-heavy workloads can cause them to accumulate faster than the vacuum can catch up, resulting in continuous database growth. The DBMS has to load dead tuples into memory during query execution since the system intermingles dead tuples with live tuples in pages.
Unfettered bloat slows query performance by causing the DBMS to incur more IOPS and consume more memory than necessary during table scans. Additionally, inaccurate optimizer statistics caused by dead tuples can lead to poor query plans.
Suppose our movies table has 10 million live and 40 million dead tuples, making 80% of the table obsolete data. Assume also that the table also has many more columns than what we are showing and that the average size of each tuple is 1KB. With this scenario, the live tuples occupy 10GB of storage space while the dead tuples occupy ~40GB of storage; the total size of the table is 50GB.
When a query performs a full table scan on this table, PostgreSQL has to retrieve all 50GB from the disk and store it in memory, even if most of it is obsolete. Although Postgres has a protection mechanism to avoid polluting its buffer pool cache from sequential scans, it does not help prevent IO costs.
Even if you make sure that PostgreSQL’s autovacuum is running at regular intervals and able to keep up with your workload (which is not always easy to do, see below), the autovacuum cannot reclaim storage space. The autovacuum only removes dead tuples and relocates live tuples within each page, but it does not reclaim empty pages from the disk.
When the DBMS truncates the last page due to the absence of any tuple, other pages remain on disk. In our example above, even if PostgreSQL removed the 40GB of dead tuples from the movies table, it still retains the 50GB of allocated storage space from the operating system (or, in the case of RDS, from Amazon). To reclaim and return such unused space, one must use VACUUM FULL or the pg_repack extension to rewrite the entire table to a new space with no wasted storage.
Running either of these operations is not an easy endeavor that one should take without considering the performance implications for production databases; they are resource-intensive and time-consuming operations that will crush query performance. The following figure shows how VACUUM and VACUUM FULL work.
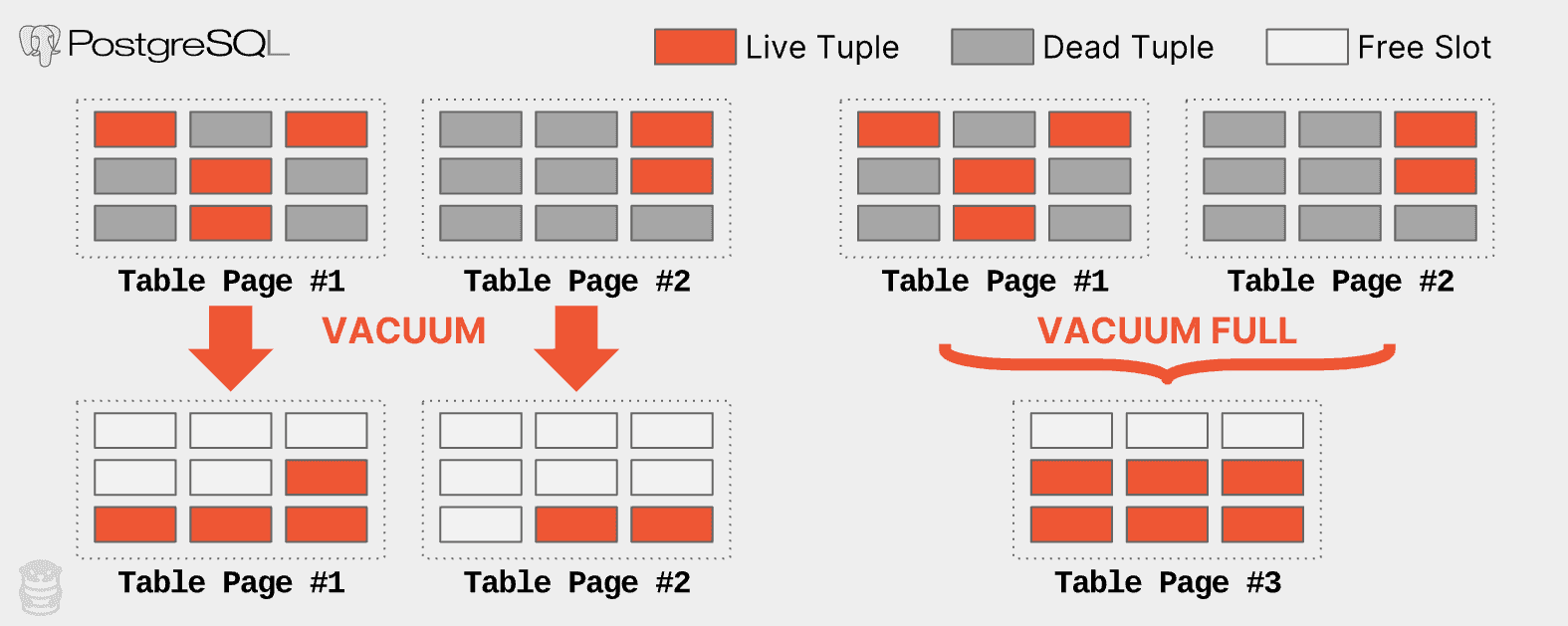
With PostgreSQL’s regular VACUUM operation, the DBMS only removes dead tuples from each table page and reorganizes it to put all the live tuples at the end of the page. With VACUUM FULL, PostgreSQL removes the dead tuples from each page, coalesces and compacts the remaining live tuples to a new page (Table Page #3), and then deletes the unneeded pages (Table Pages #1 / #2).
Problem #3: Secondary index maintenance
A single update to a tuple requires PostgreSQL to update all the indexes for that table. Updating all the indexes is necessary because PostgreSQL uses the exact physical locations of a version in both primary and secondary indexes. Unless the DBMS stores the new version in the same page as the previous version (HOT update), the system does this for every update.
Returning to our UPDATE query example, PostgreSQL creates a new version by copying the original version into a new page just like before. But it also inserts entries pointing to the new version in table’s primary key index (movies_pkey) and the two secondary indexes (idx_director, idx_name).
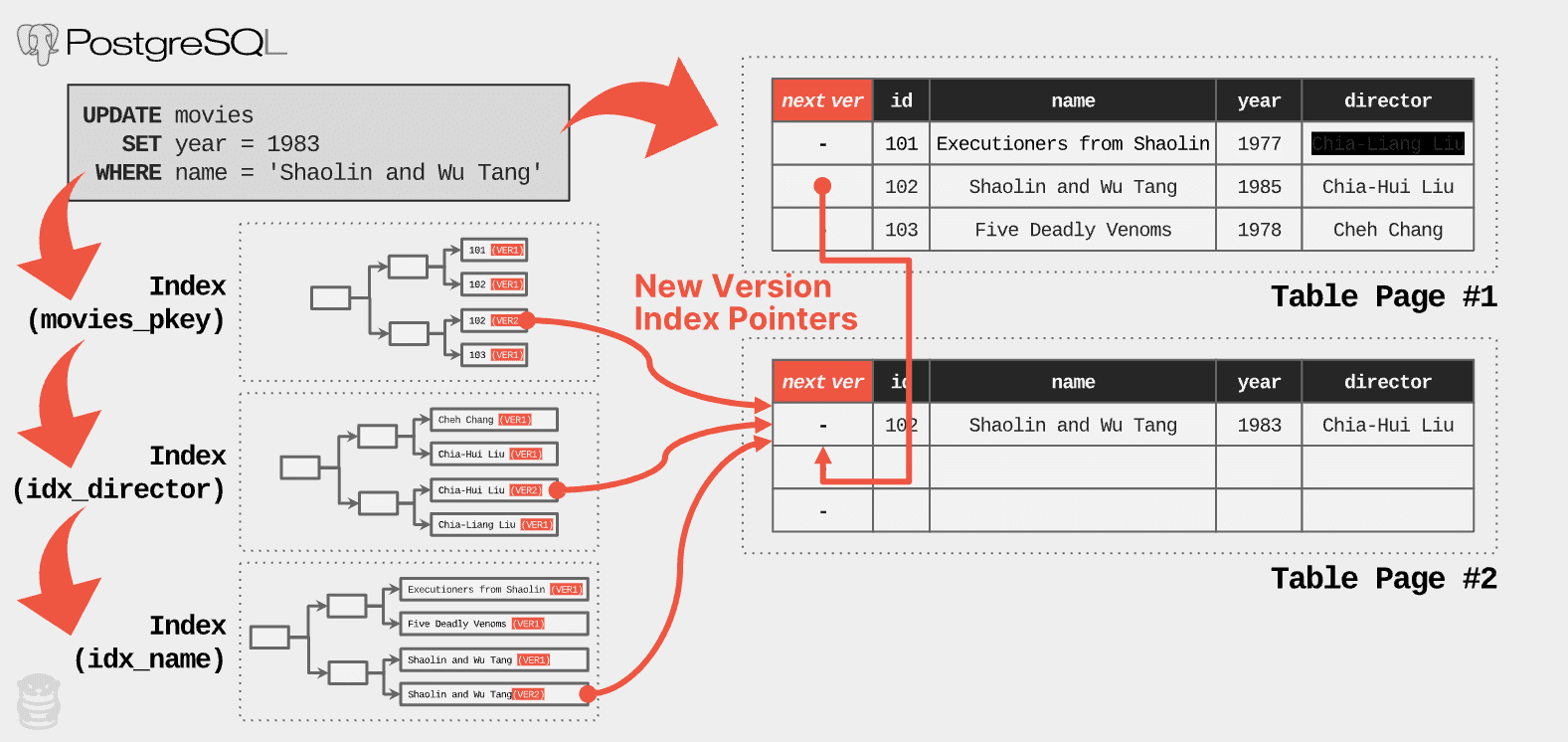
Example of PostgreSQL index maintenance operations with a non-HOT update. The DBMS creates the new version of the tuple in Table Page #2, and then inserts new entries that point to that version in all the table’s indexes.
The need for PostgreSQL to modify all of a table’s indexes for each update has several performance implications. Obviously, this makes update queries slower because the system has to do more work. The DBMS incurs additional I/O to traverse each index and insert the new entries. Accessing an index introduces lock/latch contention in both the index and the DBMS’s internal data structures (e.g., buffer pool’s page table).
Again, PostgreSQL does this maintenance work for all a table’s indexes, even if queries are never going to use them (by the way, OtterTune automatically finds unused indexes in your database). These extra reads and writes are problematic in DBMSs that charge users based on IOPS, like Amazon Aurora.
As described above, PostgreSQL avoids updating indexes each time if it can perform a HOT write where the new version is on the same page as the current version. Our analysis of OtterTune customers’ PostgreSQL databases shows that roughly 46% of updates use the HOT optimization on average. Although that’s an impressive number, it still means more than 50% of the updates are paying this penalty.
There are many examples of users struggling with this aspect of PostgreSQL’s MVCC implementation. The most famous testament of this is Uber’s 2016 blog article about why they switched from Postgres to MySQL. Their write-heavy workload was experiencing significant performance problems on tables with many secondary indexes.
Oracle and MySQL do not have this problem in their MVCC implementation because their secondary indexes do not store the physical addresses of new versions. Instead, they store a logical identifier (e.g., tuple id, primary key) that the DBMS then uses to look up the current version’s physical address. Now this may make secondary index reads slower since the DBMS has to resolve a logical identifier, but these DBMS have other advantages in their MVCC implementation to reduce overhead.
Side comment: There is an error in Uber’s blog post regarding PostgreSQL’s version storage. Specifically, each tuple in PostgreSQL stores a pointer to the new version, not the previous one, as stated in the blog. This results in an O2N version chain ordering rather than the N2O version chain erroneously claimed by Uber.
Problem #4: Vacuum management
PostgreSQL’s performance relies heavily on the effectiveness of the autovacuum to remove obsolete data and reclaim space (this is why OtterTune immediately checks the health status of the autovacuum when you first connect your database). It does not matter if you are running RDS, Aurora, or Aurora Serverless; all variants of PostgreSQL have the same autovacuum issues.
But making sure that PostgreSQL’s autovacuum is running as best as possible is difficult due to its complexity. PostgreSQL’s default settings for tuning the autovacuum are not ideal for all tables, particularly for large ones. For example, the default setting for the configuration knob that controls what percentage of a table PostgreSQL has to update before the autovacuum kicks in (autovacuum_vacuum_scale_factor) is 20%. This threshold means that if a table has 100 million tuples, the DBMS does not trigger the autovacuum until queries update at least 20 million tuples. As such, PostgreSQL may unnecessarily keep around a lot of dead tuples in a table (thereby incurring IO and memory costs) for a long time.
Another problem with the autovacuum in PostgreSQL is that it may get blocked by long-running transactions, which can result in the accumulation of more dead tuples and stale statistics. Failing to clean expired versions in a timely manner leads to numerous performance problems, causing more long-running transactions that block the autovacuum process. It becomes a vicious cycle, requiring humans to intervene manually by killing long-running transactions.
Consider the graph below that shows the number of dead tuples in an OtterTune customer’s database over two weeks:
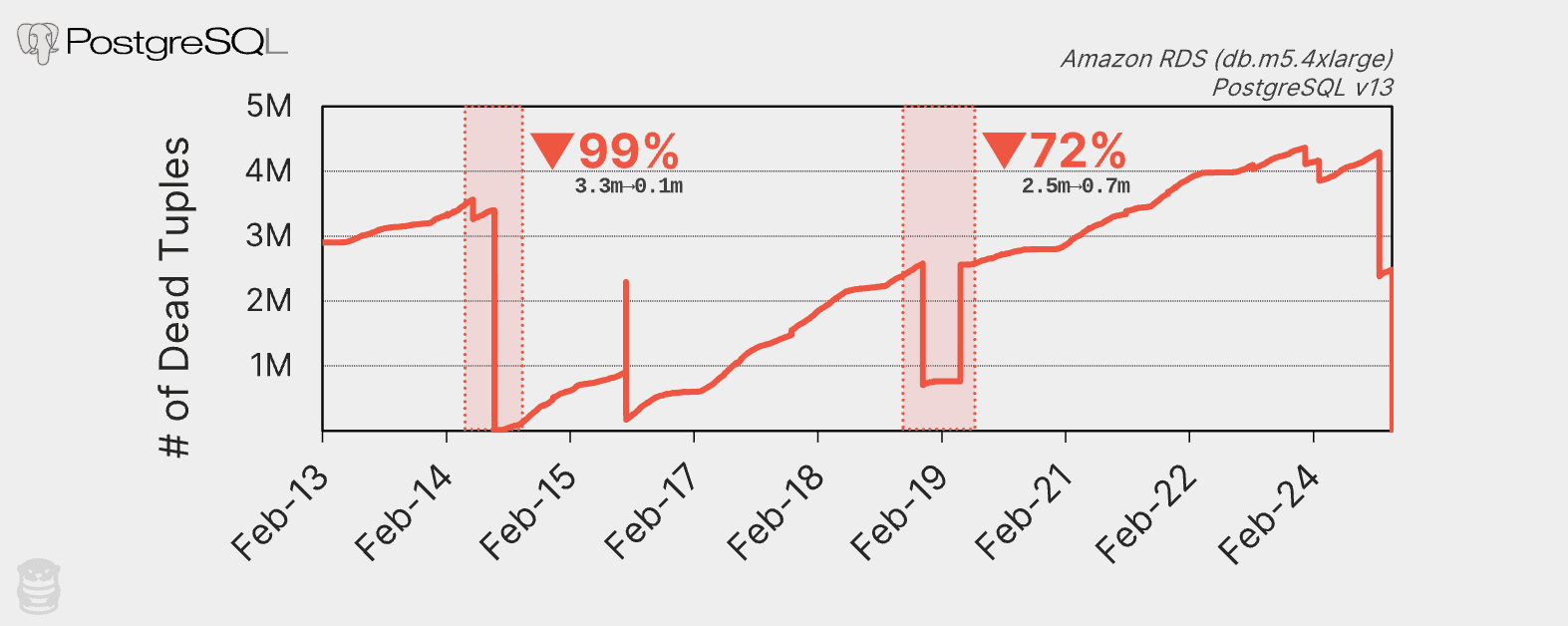
The number of dead tuples over time in a PostgreSQL Amazon RDS database.
The sawtooth pattern in the chart shows that the autovacuum performs a major clean-up about once every day. For example, on February 14th, the DBMS cleaned up 3.2 million dead tuples. This graph is actually an example of an unhealthy PostgreSQL database. The chart clearly shows an upward trend in the number of dead tuples because the autovacuum cannot keep up.
At OtterTune, we see this problem often in our customers’ databases. One PostgreSQL RDS instance had a long-running query caused by stale statistics after bulk insertions. This query blocked the autovacuum from updating the statistics, resulting in more long-running queries. OtterTune’s automated health checks identified the problem, but the administrator still had to kill the query manually and run ANALYZE after bulk insertions. The good news is that the long query’s execution time went from 52 minutes to just 34 seconds.
Concluding remarks
There are always hard design decisions one has to make when building a DBMS. And these decisions will cause any DBMS to perform differently on varying workloads. For Uber’s specific write-intensive workload, PostgreSQL’s index write amplification due to MVCC is why they switched to MySQL.
But please don’t misunderstand our diatribe to mean that we don’t think you should ever use PostgreSQL. Although its MVCC implementation is the wrong way to do it, PostgreSQL is still our favorite DBMS. To love something is to be willing to work with its flaws (see Dan Savage’s “The Price of Admission”).
So how does one work around PostgreSQL’s quirks? We cover more about what you can do in our follow-up blog.