Jan 30, 2023
How Amazon RDS replication works and why the FAA’s database problem won’t happen in AWS

On January 11, 2023, all flights in the US were grounded because of a Federal Aviation Administration (FAA) NOTAM system outage. According to the FAA, the outage was due to a corrupt database file. An engineer then tried to replace the file with a backup but it turned out that the backup file was busted too. FAA officials said that it was an “honest mistake that cost the country millions [of dollars].”
This is a pretty big fuck up. And it shows the importance of high-availability and reliability for mission-critical systems. It’s 2023 after all. Such a failure shouldn’t happen for such a service. But the FAA’s system is 30 years old. We don’t know the details about their system and how the file got corrupted in the first (e.g., bit rot, software error), but clearly the FAA’s database game was weak.
Since databases are the most important things in the world, we want to discuss how replication works in Relational Database Service (RDS) for both PostgreSQL and MySQL to ensure that your database continues to operate even when one of its parts fails or you get locked up. But as we describe below, we see people that don’t set up enable replication properly for their production databases.
For OtterTune’s customers, 70% of production Aurora clusters have read replicas. But only 32% of production non-Aurora RDS instances are replicating to at least one standby instance
There are two parts of this story. The first is how to ensure that the database’s storage is replicated. Amazon RDS stores Elastic Block Storage (EBS) to maintain multiple copies of the files. Using EBS this way is not that interesting from a database perspective because the DBMS does not know about this replication. Furthermore, it does not solve the downtime issue that hit the FAA.
If the DBMS instance crashes, you have to either wait for the instance to come back online (or start a new one) and then recover the database. The more interesting challenge is how to ensure that if the DBMS crashes, the system can still stay online with minimal disruption and without any data loss.
We’ll discuss how regular RDS databases achieve this first, then we’ll talk about how Aurora is different.
How Amazon RDS replication works
When you delete a file on your laptop by accident, you first see whether there is a backup of that file. The idea behind high-availability database systems is similar, and redundancy can make a system more robust and fault-tolerant against unexpected failures. A primary instance of the DBMS replicates the database to a standby replica instance. Some part of the system designates the replica as the new primary if the primary crashes or becomes unavailable. This failover process is either initiated from the replicas themselves or an external service. In the case of AWS, RDS coordinates this failover process.
With an Amazon RDS instance with Multi-AZ, the primary runs in one availability zone (AZ) and then replicates data to standby instances located in a different AZ. Amazon’s Availability Zones are locations within a region that are isolated from each other (e.g., us-east-1a vs. us-east-1b). Otherwise, an issue affecting an entire AZ can simultaneously cause outages for both primary and standby instances. When AWS detects a failure in the primary, it automatically fails over to a standby instance.
Amazon RDS provides two types of Multi-AZ deployments that differ based on the number of standby instances. The first type is the Multi-AZ deployment with one standby instance, which limits applications to accessing data solely from the primary instance. The standby instance, in this type of deployment, is not exposed to applications.
The second type of deployment is the Multi-AZ deployment with two readable standbys. In this case, applications have the ability to read data from both standby instances and also read and write data from the primary instance. This type of deployment provides additional read capacity and faster failover, ensuring higher availability and fault tolerance.
To understand how the replication works, let’s consider read-only workloads first. In this case, data in the primary instance does not change, so we only need to copy all the data to the standby instance once. For workloads with writes (e.g., INSERT, UPDATE, DELETE queries), the primary instance must propagate changes to the replica.
In a Multi-AZ DB instance with two readable standbys deployment, the replication process is accomplished through log shipping. Both MySQL and PostgreSQL use redo logs to record write changes. These DBMSs use different names for these logs, but they are essentially the same thing: MySQL calls them the binary log (binlog), and PostgreSQL calls them the write-ahead log (WAL).
During the replication, the primary DB instance continuously sends the latest redo log entries to both standby instances. These standby instances subsequently store the redo log on disk and apply the changes to their local databases.
After a standby instance receives the latest redo log and saves it on disk, it sends an acknowledgement to the primary instance. The primary instance will only commit a transaction after receiving an acknowledgement from either of the two standbys, ensuring no data loss during failover.
For example, suppose the application starts a transaction that changes the database on the primary. When the application attempts to commit (i.e., save) those changes, the primary waits until at least one of the standby servers acknowledges that it has stored the redo log entries on its local disk before the primary tells the application that the changes are saved (i.e., committed).
Now, if the primary crashes, a replica which has the latest redo log entries becomes the new primary. The new primary can apply the redo logs to the database, ensuring no loss of data from previously committed transactions (i.e., the Durability guarantee in ACID). Of course, transactions will take longer to commit because of the extra communication costs.
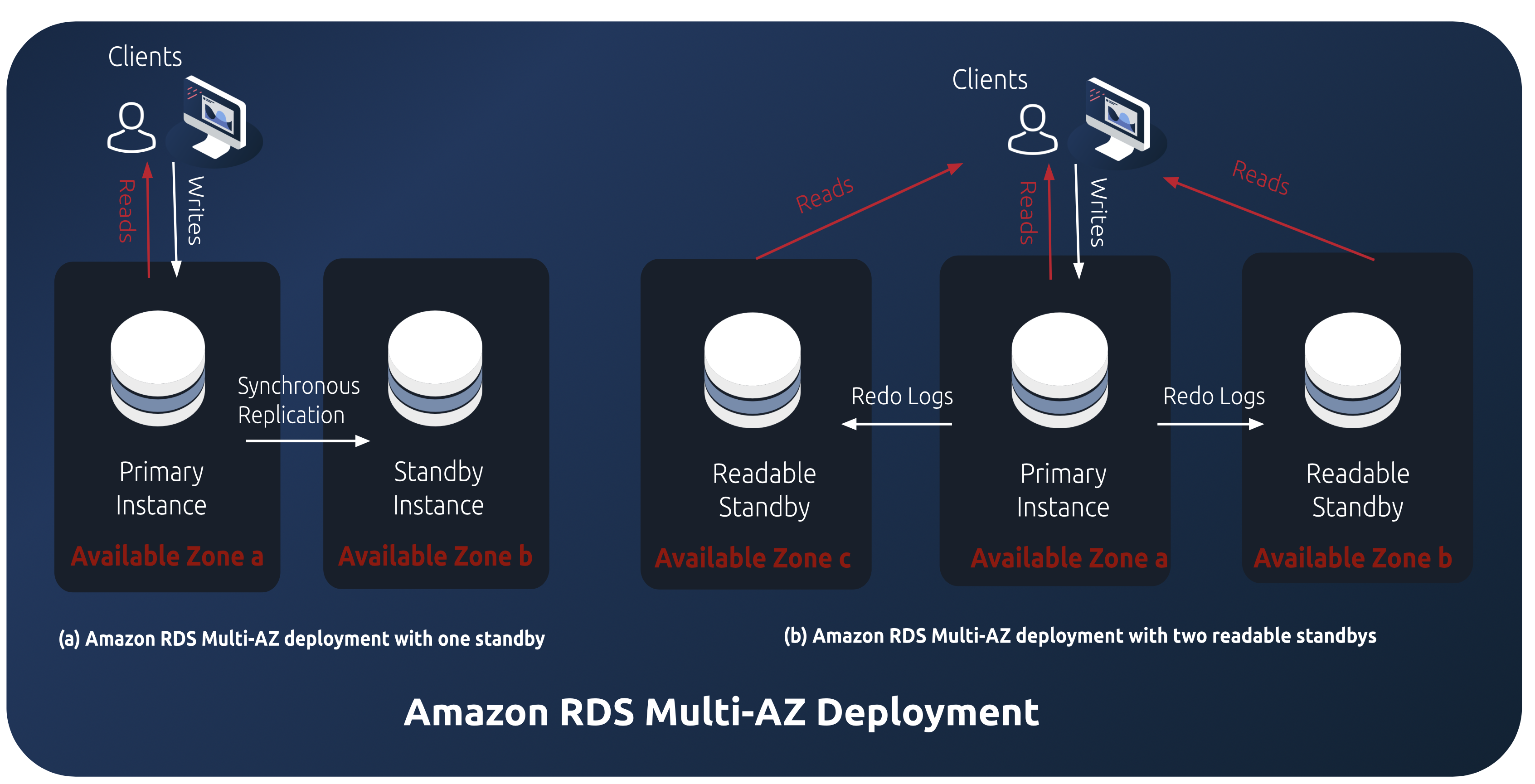
In a Multi-AZ DB instance with one standby deployment, it synchronously replicates data to the standby database. Instead of shipping redo logs described above, it replicates all changes at the storage level. When an application writes data to the primary instance, the write is sent first to the EBS volume attached to the primary instance, and then to the EBS volume attached to the standby instance.
Only after the data is successfully written to both EBS volumes is the transaction committed. The replication process is synchronous, meaning that the primary instance will not commit a transaction until it receives the acknowledgement that both the primary and standby instances have successfully written the data. This guarantees that the primary and standby instances are always in sync, eliminating the risk of data loss during failover.
How Amazon Aurora replication works
Aurora MySQL and Aurora PostgreSQL replicate data slightly differently than their RDS counterparts. For this discussion, we will refer to both systems as “Aurora” as they use the same replication procedure in their storage layer. Each Aurora storage node includes a computational component that natively processes redo log entries and applies them to database pages. This is the “secret sauce” that Amazon created for this service.
Aurora stores each database in a cluster volume that maintains multiple copies across different AZs. In an Aurora cluster, there is one primary instance that supports read and write operations, and multiple read-only replica instances. All instances connect to the same cluster volume in the storage layer. If a primary instance fails or crashes, one of the replica instances takes over as the new primary.
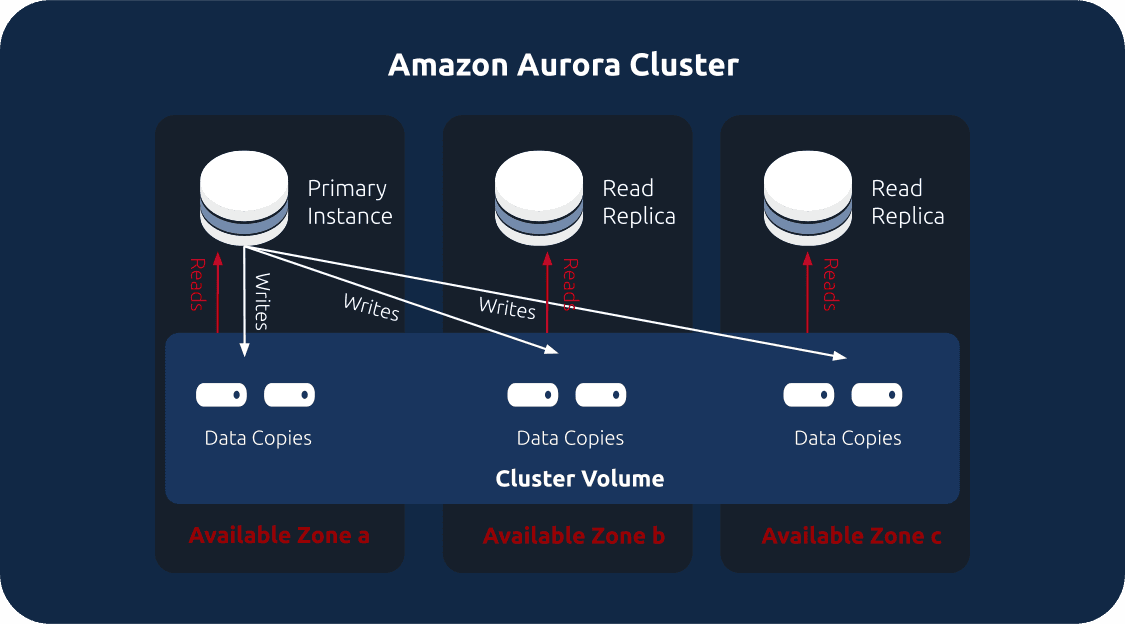
When handling a write request, Aurora sends data to six storage nodes across three AZs and waits for the acknowledgment from at least four nodes before the write is committed (i.e., quorum writes). Replicating the data to six nodes can generate huge network IO, but the system only sends redo log records to minimize network traffic. Each storage node asynchronously applies log records to data pages.
By maintaining six copies of the data, Aurora detects failures in the disk volumes and repairs them using the data in other volumes. It can tolerate at most three damaged copies out of six copies. Even if three copies are damaged, Aurora can still rebuild them from other intact copies. This repair process is automatic. You do not need to hit up somebody on their pager at 2:00 am to get them back into the cut to manually copy a file like the feds tried.
Why the FAA’s problem can’t happen in Amazon RDS
Given all this, there are several reasons why we are so sure that you are not likely to have the NOTAM-style problem for your MySQL and PostgreSQL databases in RDS.
First, Amazon does not allow you to modify database and log files manually. This means nobody can log into nodes and manually overwrite files like the FAA’s engineer, which is a common practice for disaster recovery in on-prem databases. This restriction avoids many human errors.
RDS also replicates data to multiple locations at the storage layer to protect it from the failure of any single component. Even in the rare event of the system going off the chain accidentally deleting or corrupting a file, the system can recover the data from other copies or historical copies (e.g., EBS snapshots).
Lastly, Amazon RDS has replicated DB instances and supports failover. It synchronously replicates data from the primary instance to other instances deployed at different AZs. If the primary DB instance crashes due to any corrupted file, it will fail over to the standby or replica instance to continue operating correctly.
But it is important to understand that while Amazon makes sure that your RDS database files are safe (i.e., you are unlikely to face a file corruption problem), they do not provide standby replicas by default. You have to manually create replicas in AWS to get this capability.
Without this, then if (when) your DBMS instance crashes, your database will be unavailable until it comes back online. In the best case scenario, the DBMS will come back in under a minute. But depending on the size of the log and the last time the DBMS took a checkpoint, it could be hours or even days!
When we examine the databases of OtterTune’s customers, we were surprised to see that not everyone is running their production databases with replicated instances. This is not an exact survey. We just checked whether the name or tag of the RDS instance contained the word prod (roughly 40% of all OtterTune databases).
For Aurora, 70% of production Aurora clusters using OtterTune have read replicas (it was roughly the same for MySQL and PostgreSQL). But only 32% of production non-Aurora RDS instances are running with at least one standby instance. The following graph shows the percentage of these databases by instance size:
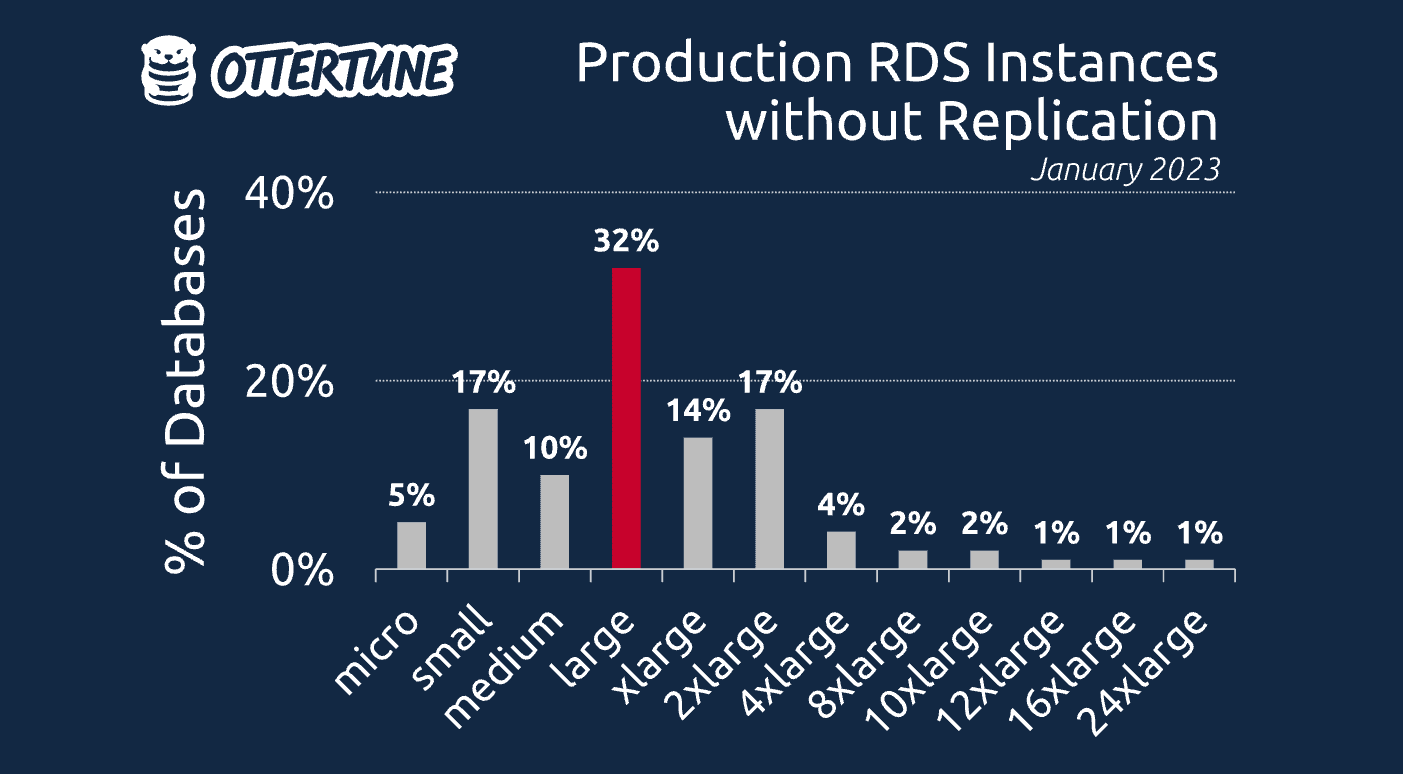
As you can see, the majority of RDS databases are large or smaller. There is a surprisingly a few of the larger instance sizes (e.g., 24xlarge) that are running without either synchronous or asynchronous replication! If the database is so important to run on an instance that costs roughly $40,000 a year, you would think that they would want to make sure that it is always available. But it doubles the costs of the deployment. So people choose to go without database replication like driving without a seatbelt. YOLO.